Speech has structure.
Now you can see it.
Traditional systems capture words. Auravoxa captures delivery — mapping how speakers talk, pause, and change over time into structured, traceable insight.
Descriptive, not diagnostic. Evidence-oriented by design.
A transcript isn't the whole conversation.
When audio becomes text, most of what makes communication meaningful is discarded.
What a transcript captures
- The words — what was said, in order.
- Keyword search — find what was mentioned.
- A summary — a compressed version of the content.
What a transcript discards
- Pause structure — when someone stopped, for how long, and where.
- Rhythm and pacing — how speech rate shifted across the session.
- Prosodic dynamics — pitch contour, intonation, and vocal energy.
- Speaker dynamics — who spoke when, how much, and how their patterns differed.
- Pragmatic markers — hedging, self-repair, disfluency, and structural hesitation.
Delivery is data. Auravoxa preserves it.
From audio to insight — session by session.
Every conversation follows a governed pipeline that preserves what transcripts discard — from ingestion to final report.
Upload Audio
Securely ingest your recording. Sessions are workspace-isolated from the moment of upload.
Extract Signals
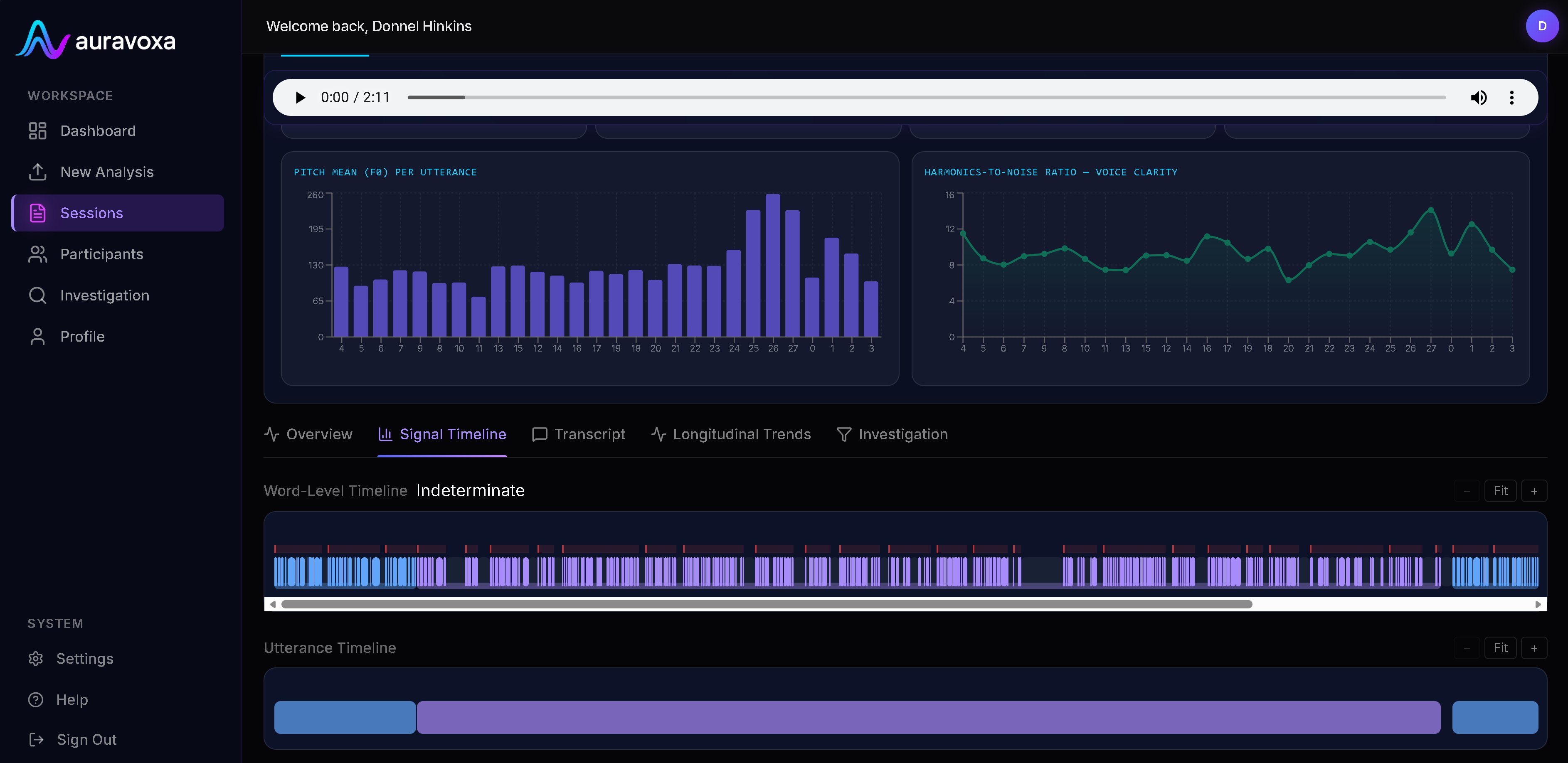
Over 100 verified speech signals are extracted per session — voice, rhythm, language, pragmatics, and more.
Analyze Sessions
Signals are attributed per utterance and per speaker, producing an interactive timeline and 7-section report across voice, rhythm, language, and conversation dynamics.
Track Patterns Over Time
Link participants across sessions. Detect baseline drift and observe how communication patterns evolve.
Export & Integrate
Export structured data as JSON or CSV. Integrate downstream workflows via the Auravoxa API.



Signal depth that goes beyond the surface.
Most speech tools give you a sentiment score. Auravoxa extracts independently measurable signals across every dimension of how something was said.
per session
Voice & Prosody
Pitch contour, intonation dynamics, vocal energy, and tonal variation across utterances.
Acoustic Profile
Measurable frequency, intensity, and spectral characteristics from raw audio.
Rhythm & Timing
Inter-word pacing, speech rate variance, tempo profiling, and articulatory fluency.
Pause Structure
Silence distribution, filled pause detection, pause density, and rhythmic variability analysis.
Language Structure
Lexical diversity, syntactic complexity, clause density, and vocabulary richness.
Pragmatic Markers
Hedging, disfluency, self-repair, back-channeling, and structural hesitation indicators.
Speaker Attribution
Multi-speaker diarization with per-speaker signal profiles and turn-by-turn attribution.
Temporal Dynamics
Time-series signal behavior across utterance boundaries and full-session trajectories.
Interaction & Context
Conversational dynamics, speaker overlap patterns, and session-level structural markers.
What you receive after every session
Per-participant signal baselines accumulate automatically with every session processed. The Longitudinal Trends view — accessible via the Signal Timeline tab — surfaces drift, comparison, and baseline evolution over time.
Longitudinal Intelligence
One session tells you what happened.
Multiple sessions tell you what's changing.
Most speech platforms analyze a recording. Auravoxa analyzes a recording and remembers prior recordings — accumulating per-speaker baselines across sessions to surface meaningful drift over time.
- Per-participant signal baselines that mature with every session
- Automatic drift detection when patterns shift from established norms
- Side-by-side session comparison across any signal family
- Designed for coaches, researchers, and organizations tracking communication over time
Multi-Speaker Analysis
Conversations are more than one voice.
Auravoxa separates speakers automatically, attributing the full signal set to each participant. Upload a conversation and receive independent signal profiles for every speaker — plus interaction-level dynamics that only emerge when two voices are analyzed together.
- Automatic speaker diarization — no manual labeling required
- Per-speaker signal attribution across all 100+ signals
- Turn-taking, overlap, and interaction dynamic analysis
- Link participants across sessions for longitudinal comparison
Analysis built for serious work.
Beneath the surface, Auravoxa applies rigorous analytical methods you won't find in conventional speech tools.
Rhythmic Variability Analysis
Auravoxa applies a novel approach to pause rhythm analysis — adapted from cardiac science — to surface variability patterns in speech timing that no conventional pause metric captures.
Governed Interpretation
AI-generated session narratives are bounded by an evidence governance layer. Interpretations are confidence-qualified and traced to observable signals — grounded in what the audio actually contains.
Traceable Signal Provenance
Every finding in Auravoxa traces back to a measurable signal. The chain from audio to interpretation is preserved and auditable — giving analysts a clear path from conclusion back to the original conversation.
Built for wherever how something is said matters as much as what was said.
Auravoxa's approach is domain-agnostic — wherever the delivery, patterns, and dynamics of conversation carry meaning, the platform adds depth.
Research & Linguistics
Rigorous, reproducible signal extraction across 100+ documented dimensions. Structured export formats including JSON and CSV for integration with research workflows.
Security & Analytic Review
Observable acoustic and delivery patterns — non-subjective, auditable, and traceable to source signals. Designed for review workflows that require a clear chain from observation to conclusion.
Communication Coaching
Track how a speaker's delivery evolves session over session. Longitudinal baselines surface meaningful change over time — giving coaches and learners concrete, signal-backed feedback they can act on.
Enterprise & Teams
Workspace-isolated multi-tenant architecture with enterprise SSO, role-based access, and API integration. Built for organizations that need interpretable data and a clear audit trail — not black-box scores.
Privacy and Security by Design
Secure Cloud Processing
Audio ingestion and analysis run in governed cloud environments with encrypted storage.
Workspace Isolation
Tenant-separated data with row-level security and no cross-organization visibility.
Role-Based Access
Configurable roles — Standard, Analyst, Admin, Enterprise — with scoped permissions per workspace.
Governed Data Handling
Structured retention policies, audit logs, and governed data lifecycle from ingestion through export.
Signal Provenance
Traceable chain from audio ingestion through signal extraction to final interpretation.
Retention Controls
Configurable data retention with governed deletion workflows and organization-level controls.
Non-Clinical by Design
Outputs are expressly descriptive. Auravoxa surfaces structure — never diagnosis, judgment, or clinical assessment.
Enterprise SSO
OIDC/SSO authentication for enterprise organizations with multi-tenant workspace access management.
Built to integrate.
Auravoxa is a platform, not a portal. Access the full signal pipeline programmatically through a REST API and flexible export formats.
REST API
Programmatic access to session ingestion, signal retrieval, report generation, and participant management.
JSON & CSV Export
Complete session signal data in machine-readable formats for downstream analysis, research pipelines, and BI tools.
Participant Linking
Link the same speaker across multiple sessions via the API to build longitudinal participant profiles programmatically.
Report Retrieval
Pull 7-section reports, signal families, and per-utterance data via API for integration into your own workflows and pipelines.
# Submit a session
POST /v1/sessions
Authorization: Bearer <api_key>
{
"audio_url": "https://...",
"participant_id": "p_abc123"
}
?families=prosody,rhythm
?format=json
Built for secure audio ingestion, session-scale analysis workflows, and governed cloud processing. GPU-accelerated pipeline on enterprise cloud infrastructure.
Methodology
Built within the Cognispace ecosystem
The Cognispace Framework is a structured model for understanding how intent, evaluation, and expression interact to produce observable behavior — across individuals, organizations, and systems. Auravoxa is built on that foundation.
Learn about the Cognispace Framework →Structured, bounded, and human-centered
Non-clinical by design
Outputs surface patterns and structure — designed to inform, not to render judgment.
Evidence-oriented interpretation
Every insight traces back to a measurable, observable signal.
Built for structured analysis
Designed to surface patterns, not render absolute judgments.
See what your audio is actually saying.
Apply for early access to evaluate the platform. Because our development focuses on rigorous signal models, space in the Private Beta is strictly limited.
Private beta — currently onboarding early design partners and technical evaluators.
Built for research, analytic review, and enterprise workflows where delivery and patterns matter as much as words.